We, too, are autonomous vehicles, groping our way forward in a world we only partly understand.
- Paul Churchland, Plato's Camera, p. 125

The diagrams at the top of the page show two different versions of a neural network, a concept from AI research. Paul Churchland argues in the book Plato's Camera that complex concepts develop using a network formation process. Neurons in the brain are organized in layers that are successively further from the sensory or motor neurons on the surface. First-order neurons fire in response to direct sensory data -- the "input" layer of the neural network shown above, where a face maps into a pattern of cell activations in the retina. Second-order neurons then fire based on patterns of response in the first layer: For example, Level-2 neuron A fires when Level-1 neurons 1, 6, and 9 fire together, but not when Level-1 neurons 1, 5, and 7 are activated at the same time. Level 2 is labeled the "compression rung" in the figure, because it compresses large amounts of data into summary measures. In version (a) of the figure, the same image can then be reconstructed from the pattern of Level-2 neural activations, which is how many of us imagine that our vision works: The eye takes a picture or film of what's happening around us, and then projects it (upside down) onto a screen in the visual cortex, where some third-person observer watches it.
However, Churchland argues that what actually happens in the brain is more like version (b) of the diagram than version (a). After the first compression of rich sensory data into a small number of patterns, Level-3 neurons then summarize the pattern of responses at Level 2 into even higher-order abstractions. This leads to a pattern-recognition function in which sensory data are eventually represented by a relatively small number of abstract concepts, each of which corresponds to a given set of characteristics in the external world. In version (b) of the face-recognition figure, just 8 yes/no neural firings provide a wealth of data about whether the eye is seeing a face at all, whether the face is male or female, and the name of the individual person whose face it is. In this view, the mind works mainly by recognition of patterns: The binary judgments made by the Level-3 neurons are associated with a specific subjective experience. The earliest visual-network pattern for most people is a set of neural firings linked to the subjective experience "mother's face."
This might seem like a very small number of data points to capture a complex experience, but AI research shows how a learning system can very efficiently store very subtle distinctions. For instance, studies of color perception ask people "is this color the same or different from that one," in order to identify the dimensions and degrees that humans use in organizing color experiences. These studies reveal that all the colors we see are discriminated from one another based on 3 basic dimensions -- hue, saturation, and brightness (or "luminosity") -- as in the left-hand figure below. You will see a similar color wheel in any computer program that lets you adjust colors -- e.g., the second diagram. Think of the rectangular colored area as a cross-section of the first diagram, where the sliding black-to-white bar on the right side moves the plane through different parts of the off-kilter double cone in the first diagram. The program manages colors in three dimensions because that's the way people perceive them. An additional layer of sophistication is provided by the right-hand figure in this row, which shows the activation of three different types of cones in the retina of the eye, which have different levels of activation corresponding to the color dimensions of white-black, red-green, and yellow-blue. Graphing the firing levels of three different types of neurons again yields a conical solid around a tilted color wheel. Even though many humans don't know (or care) that colors can be represented in a three-dimensional graphical space with hue, saturation, and brightness as the X, Y, and Z axes, their brains are doing exactly this -- thousands of colors represented by three variables.



So far, so good: It makes sense that our perceptions of the world would correspond to the underlying biology of our eyes, and that we would design computers with dimensions that map onto our experiences. The final diagram below is even more interesting: It was produced by an AI program instructed to learn how to represent colors using as few dimensions as possible. The program wasn't told about hue, saturation, and brightness, only that colors are different from one another. The program independently discovered a three-dimensional solution that corresponds almost exactly to the familiar color wheel. It appears, then, that three variables are the optimal way to represent colors.

This view of the Narrative System is of course a model, one based on recent AI research, and it may ultimately turn out to be wrong. But the measure of any model is whether it allows us to make sense of the world, and this particular model helps us make sense of several other findings:
1. It explains why our phenomenological experience of the Narrative System is typically "sparse" or "thin" compared, for instance as described by Eric Schwitzgebel or C.S. Lewis. Narratives are based on very small amounts of data -- in the face example, the firing or not-firing of just eight 3rd-level neurons in the neural net compared to 4096 cells at the level of perception. If narratives are actually pattern recognitions, and not reproductions of an image, a sound, or a sensation, they would almost necessarily have a subjective "feel" that is less rich and nuanced than the original.
2. It explains why the Narrative System is slower than the Intuitive System. A key point in TMT is the hypothesis that only the Intuitive System produces behavior. Both the primary visual cortex and the primary auditory cortex have 6 major layers of neurons, rather than the three shown in the simplified example at the top of this page. How long it takes an electrochemical impulse to travel the length of a neuron varies depending on the length of its axon, but an average might be about 10 milliseconds. In neural time, 60 milliseconds is very slow; the simplest reflex arc (i.e., when a doctor taps your knee and your leg jerks) takes only 15-30 milliseconds to produce a muscle contraction. The argument in TMT is that behaviors in general are more like the reflex arc; conceptual understanding happens later in the cycle and thus can inform later behaviors but not the current one.
3. It uses a feedback loop to shape responses. Most body systems involve feedback loops, like the sympathetic nervous system producing a fight-or-flight response and the counter-action of the parasympathetic nervous system calming a person down again afterwards. The general goal of each body system is to maintain homeostasis, a steady state. Churchland argues that neural systems work in the same way, with ascending neurons signalling the higher-level neurons that contain abstract concepts, and descending neurons providing feedback to the sensory neurons to let them know whether they have seen a familiar pattern or produced an understandable representation of the world.
4. It fits with the threshold-activation property of neurons, which is that the more times a neuron has been activated by a particular stimulus the easier it becomes to activate in similar circumstances. This means that we each develop certain comfortable and familiar ways of interpreting experiences, based on the conceptual maps that we have most often activated in the past. It also means that as we get older and our habits of thinking become more ingrained, we have a harder time seeing things differently from how they appeared to us in the past -- a phenomenon that explains both the evident creativity of children, who have less well-developed conceptual frameworks, and the common experiential truth that life becomes less vivid with age.
5. Because it responds to patterns of stimuli rather than propositional logic -- a map, Churchland says, and not a script -- it helps us to understand one important way in which the Narrative System can be fooled. Different parts of a person's cognitive map may be activated by stimuli that seem to correspond to multiple categories, as illustrated by the faces shown below:
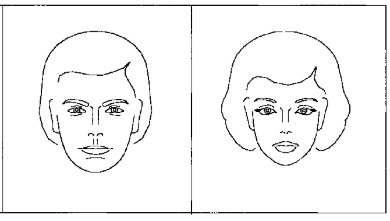

Notice that each pair looks like a man (on the left) and a woman (on the right). But the left-hand face in the first pair and the right-hand face in the second pair are actually identical. It's the contrast with a hyper-masculine or hyper-feminine face that makes the gender-neutral face appear masculine in one context and feminine in the other. This optical illusion shows how the concept that is activated in the brain doesn't have a one-to-one link with the stimulus that activates it. Instead, it is a relative judgment about where the stimulus falls on a cognitive map that covers a range of territory.
6. It allows for multiple layers of abstraction. As described in the original article on Two Minds Theory, the Narrative System is good at making judgments like "the animal sitting by my chair is named Midnight; he is a poodle; a poodle is a dog; a dog is a mammal; and a mammal is a living creature." Through this system of successive abstractions I can interpret any of Midnight's specific behaviors with reference to what I know about dogs, mammals, or living creatures in general, and thereby predict how he is likely to act in many possible situations. In the following example, the pattern of neural firings associated with each individual breed of dog are more similar to each other than the patterns associated with different breeds of cats, which is how we can recognize the commonality between a Pekingese and a Great Dane at the conceptual level (top half of the figure) even though they are associated with quite different sensory experiences (bottom half). At an even higher conceptual level, a third level of the diagram might further show that cats and dogs are more like each other than they are like insects, automobiles, or furniture. Higher-order networks of association are ultimately the way in which we use concepts to make sense of our experiences.

7. It includes time or motion as an essential feature of each concept. In traditional views of cognition, the idea of a "thing" was differentiated from the idea of its behavior or processes in which it was involved. But the world around us is in constant motion, and part of what neurons habituate to is a pattern of changes over time. Including time or motion as part of every concept not only makes the world more predictable, it helps to explain subtle associations that we may not even be fully aware are part of our concept. My wife dislikes spiders, for instance, in part because of "the way they move." A spider that moved differently would, in some sense, not be a spider at all.
8. Finally, it provides an explicit explanation for how creativity works. In Churchland's view, the only difference between sensory experience and creative imagery is the direction of neural activation. In a perception of the real world, patterns of neural activity activate higher-level concepts. In the use of imagination, a higher-order concept sends neural signals back down to the sensory level, where the neurons visualize how that concept would appear in the real world. The downward motion from concepts to images explains the sort of "social imagination" that the Narrative System does well, and also more fanciful types of imagination like the combination of eagles and lions to produce griffins.
Churchland concludes that by joining a sensory system to a concept-developing mechanism, and then connecting concepts back to motor neurons, humans are able to navigate the world exactly in the way that self-driving cars do. This explanation is somewhat lacking from a TMT perspective, because it doesn't accommodate the fast-versus-slow distinction in which Narrative thought is separate from behavior. It also denies free will, an issue that in TMT is still open to debate. But where Churchland's model is excellent is in its explanation of how concepts emerge and function in relationship to sensory experience. Even though this proposed model of thinking relies on neuroscience and metaphors from AI research, Churchland concludes that "Plato would approve": The model describes a process by which the mind extracts objective and enduring features from a constantly changing stream of sensory data about the world. This fits with the Platonic distinction between observational reality and enduring universals. It also fits well with the distinction between fast Intuitive thought versus slower and more abstract Narrative thought in TMT.
Comments
Post a Comment